Hi,
I’m pretty new to all this and have installed proxmox on an old laptop. The laptop has two drives - 250Gb ssd and a 1Tb HDD. What I would like to do is have MariaDB on the HDD, and then I plan to write and deploy an app on the ssd drive that will populate the database, and also run analysis on the data.
So far I’ve installed proxmox on the 250Gb SSD and have started a VM running Ubuntu Server with ample space left for the app. I’ve also mounted the hdd as LVM and am able to see the drive through the node shell pve1.
Now I’m a bit stuck I’m not sure what path I would need to use to get the app to write to the database given that I cant see a clear path (I guess I was expecting a filepath or something similar). Would i need to put another VM on the HDD and connect through sockets or should it be accessible directly from the ssd drive.
Just to add, you can probably tell I’m massively new to all this so I’m also open to the idea that my configuration is completely wrong and needs rebuilding. Also, apologies if this question is a little jumbled and unclear and if there’s any further clarification I can give please let me know.
Thanks in advance.
Welcome to the forum!
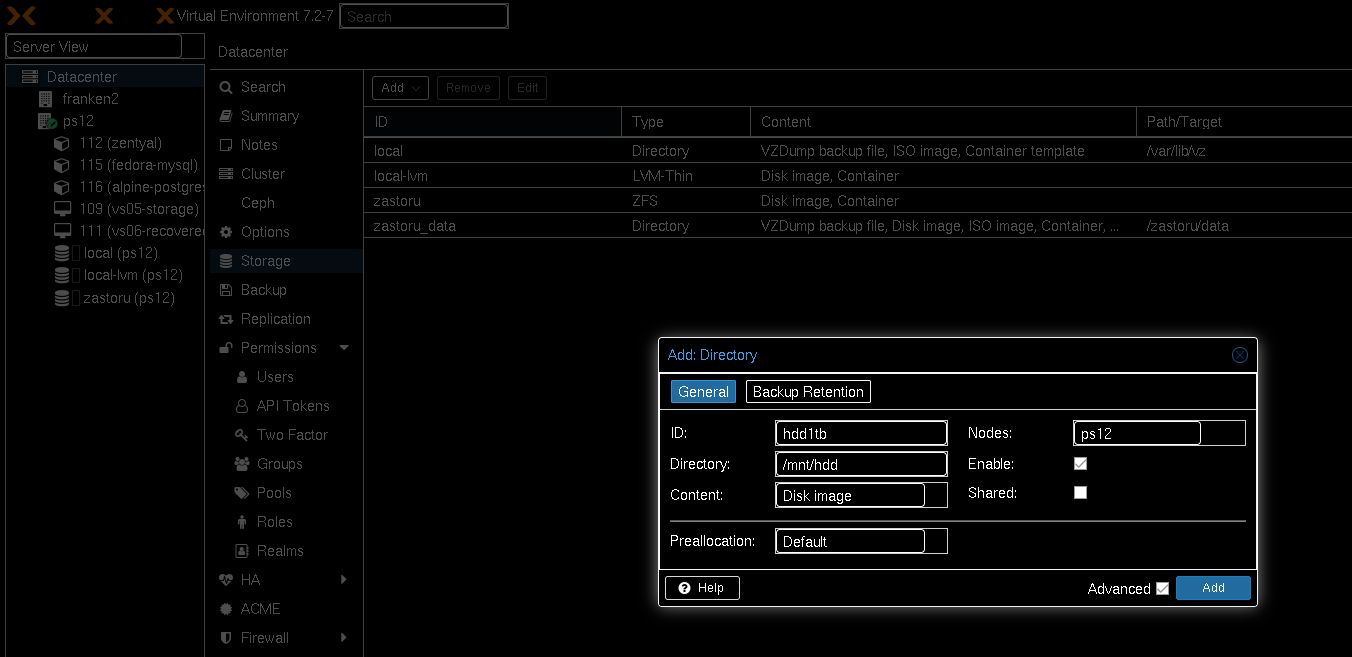
Under Datacenter → Storage → Add → Directory.
If you have a cluster, this would add it to all your servers, but since you are only running it on a laptop, you’ll only have one server there. Speaking of which, I hope your program is not important, or that you take plenty of backups, because you have no redundancy. I would attach a USB HDD and back up your VM and dump your DB on it. You could also make a cheap NAS with a RockPro64 or pony up some more for an Odroid H3, which will be able to serve more than 1 host (I’ve had a bunch of HP ProLiant MicroServer Gen8, probably around 5, serving about 12 proxmox hosts - not my proudest infrastructure, but at least I wasn’t the one who had the bright idea to use non-rackable, but stackable servers).
Useless rant
At my previous workplace, when I had a bunch of servers with random configs and I didn’t want to run all the VMs on the local storage on a single server, I exported the path on one server with large amounts of storage via NFS and mounted the export on all the servers, including the local one.
That way I could run and migrate VMs as if they were running on a NAS (I had plenty of NASes too, but they were starting to get full and I needed to do some cleanup and some maintenance here and there). Migrating VMs when using local LVM or directory takes longer, because you have to move the disk too, not just the RAM contents, which I didn’t want. Of course, single points of failure still apply more than ever, but depending on what you’re doing, it’s fine.
1 Like
Thanks so much for taking the time to respond. Going off of your response I think I was maybe approaching the whole thing in the wrong way. I was trying to set the project up as server based but expecting it to run like a laptop. I think I’ve got it sorted now. I’ve set up a separate VM on the HDD with MariaDB.
I just need to figure out the parameters for mysql connector so that it connects to the data base and I think I’m set.
As for the importance, its all very basic and is just intended for me to play around with and get some practice. Part of that will be backups but for now i’ll be happy if I can just get something working.
Thanks again for responding, really appreciate it.
1 Like
Kind reminder that there is LXC on Proxmox, it can help you with the battery (and general resource consumption allocated to your programs, instead of used to emulate a CPU and other peripherals).
For me, mariadb was working fine on Fedora LXC, people reported that it was not working on Ubuntu LXC on the forum, for unknown reasons.
I don’t know your background or knowledge in DBs, but make sure you take dumps of the DB, not file system backups of your VM, otherwise your DB will be inconsistent and unrecoverable. There’s also binary logging (optional, but which you can use, combined with table locks to create file system snapshot in a consistent DB state, then copy the contents of the snapshot to a remote location, but that is way more complicated than a data dump - besides, dumps take a couple of seconds to a few minutes for a small db, fs backups only make sense on really large dbs).