I ran a Gitlab CE home server for a while on a VM. The only thing I could say on somewhat of a negative side is, if you don’t keep up with the updates it can be a challenge to get things back to the latest revision.
I never tried their Docker Image, but that seems like a good prospect.
Yeah the Docker image makes it lots easier to catch up if you skipped a major version that requires migration. It’s just a matter of sequentially running the images for the skipped releases, which are all in the Docker Hub. \o/
@Buffy - Question. How do you deal with the hostname(s) on your instance? If I recall, I had to use IP addresses, and that caused me problems with deployments in various scenarios.
In the end, I just went with an HA implementation using Github, Bitbucket, and Gitlab. I used Github as the master, and BB & GL for StandBy / DR.
Ours is set to use different ports on the host, 30000 for the web part and 30001 for ssh. Those are the only ports we expose for the Docker image (PostgreSQL, etc, stay internal to it).
When your infrastructure is small, this works, but what usually happens is people install the docker versions of nginx, haproxy or traefik on 2 or 3 different worker nodes and giving them access to the ports 80 and 443 locally. Then, docker (and any oci container) solves their DNS resolution internally. You configure the reverse proxy to listen to a vhost (basically a domain) and point that domain to the container’s name. Something like
Obviously the above is pseudo-config, I don’t remember how the conf goes, but that’s the gist of it.
This way, you can’t even access the resources without going through a reverse-proxy first, which is pretty secure. The same would apply when splitting containers into multiple pods, like gitlab in one pod would have its configuration point out to the container name of postgres, which would get resolved internally by docker / k8s. Internal to the container network, they talk on normal ports (or at least the ports that are configured inside the conf files to listen on).
And this only works with containerized reverse proxies, because a normal install will not be able to resolve the internal container hostname.
I’ve been wondering about this. Specifically how to organize my configuration files outside of the actual host or container, so that I can reproduce the exact setup when needed.
For example I would use Nginx listening on ports 80 and 443 and forward requests to other instances similarly running on their own containers. How do I pass this configuration to the nginx instance? I would assume some git repository as we’ve discussed but is it save to make this configuration public?
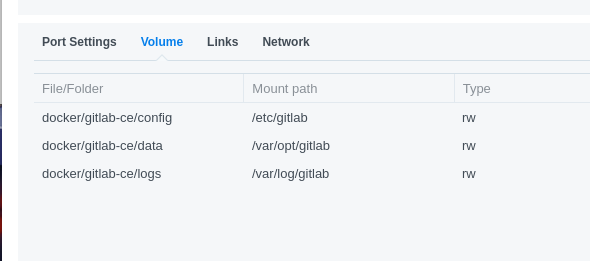
Gitlab’s Docker container maps its config directory to a host directory:
That way you back them up separately (you should still run Gitlab’s backup, too, so that you backup the database).
I wouldn’t put anything sensitive on non-locally-hosted repositories, but if you have your own then you can, either as a script or an Ansible playbook.
I think otherwise it isn’t so much passing the config on as having a documented standard for how you assign addresses and ports, then setting them up with the same parameters.
I believe you can do that with docker-compose, or by simply modifying the nginx conf and back it up, like Buffy mentioned.
I have used nginx and haproxy in the past and I’ve been satisfied, but I’ve seen reviews of Traefik, which is a cloud native reverse proxy. I believe Traefik has the ability to auto-detect new instances in docker, or something like that and do some weird voodoo in the back, so you don’t have to configure / map containers manually in a conf file, like you would traditionally in nginx or haproxy. I haven’t used it though and at this point, there doesn’t seem like I will, but it’s worth taking a look at it.
I’ve been recommended Traefik before for exactly those type of reasons, it’s cloud native and works really well with containers. But is a little harder to learn, still very much in development so the documentation is confusing and changing… I’m going to wait a little while until I’m more comfortable doing things the “hard way” (meaning Nginx) for now.
As for docker-compose that’s what I’m planning on using, and simply bind mount the configuration files that nginx needs to forward requests. But, at the same time there’s a chance that reverse-proxy container is deployed in a different node than the one with the configuration file (I’m currently using Docker Swarm) so maybe is worth simply building a new container with these files already built into it. I’m not sure still how volumes work when using orchestrators, but I really don’t want to dive into Kubernetes as that’s probably too complex for me.
I love the recommendations on just using what you have for your home lab and watching the power bill. @jay had the advice on one of his videos to shut the server down at night when no one is accessing the network, and to use wake on lan to bring the servers back up when you want them working. I’ve done this in my labs. I have two labs with nothing that is mission critical (so mistakes can be made and no one is prevented from working).
Work Lab:
1 - Raspberry Pi 1 (on all the time, so I can ssh or vpn into this box and “wake” my server on the work network)
1 - Old i3 laptop with 4 Gigs of RAM (plenty of horse power for what I have been doing on it, sleeps most of the time unless I want to use the CRM on it or try something new on Debian 11)
Home Lab:
1 - Raspberry Pi 3 (on all the time running Pi Hole)
1 - Dell OptiPlex i3 with 4 Gigs of RAM (on all the time, running Fedora Server, main source of truth for Syncthing, all other Syncthing clients sync just with this server, and just this machine keeps three copies of every file that is synced)
1 - AMD older 2 core CPU and 8 Gigs of RAM Desktop built from salvaged parts of a few desktops destined for recycling with a Btrfs storage pool (on only when main home server is rsyncing its Syncthing data to is as a back up, then shutdown after script runs)
Also wanted to mention that if you want to run a private “git server” you could just run git on one of your home lab machines using bare repos and ssh. If you are not collaborating with others, you don’t really need a web interface since it is going to be you pushing and pulling to the repo. I’m running this on the work RPi 1 since it is always on, and can be accessed from my clients at home or at work. I like keeping all of my dotfiles on it just to make sure I never accidently push a config file that has private information to Github. I wrote about this whole set up here.